three methods to load model 1. download model in openxlab 2. download model in modelscope 3. offline model |
||
|---|---|---|
| .. | ||
| cli_internlm2.py | ||
| cli_qwen.py | ||
| README_EN.md | ||
| README.md | ||
| requirements_qwen.txt | ||
| web_qwen.py | ||
Deploying Guide for EmoLLM
Local Deployment
- Clone repo
git clone https://github.com/aJupyter/EmoLLM.git
- Install dependencies
pip install -r requirements.txt
-
Download the model
-
Model weights:https://openxlab.org.cn/models/detail/jujimeizuo/EmoLLM_Model
-
Download via openxlab.model.download, see cli_internlm2 for details
from openxlab.model import download download(model_repo='jujimeizuo/EmoLLM_Model', output='model') -
You can also download manually and place it in the
./modeldirectory, then delete the above code.
-
-
cli_demo
python ./demo/cli_internlm2.py
- web_demo
python ./app.py
If deploying on a server, you need to configure local port mapping.
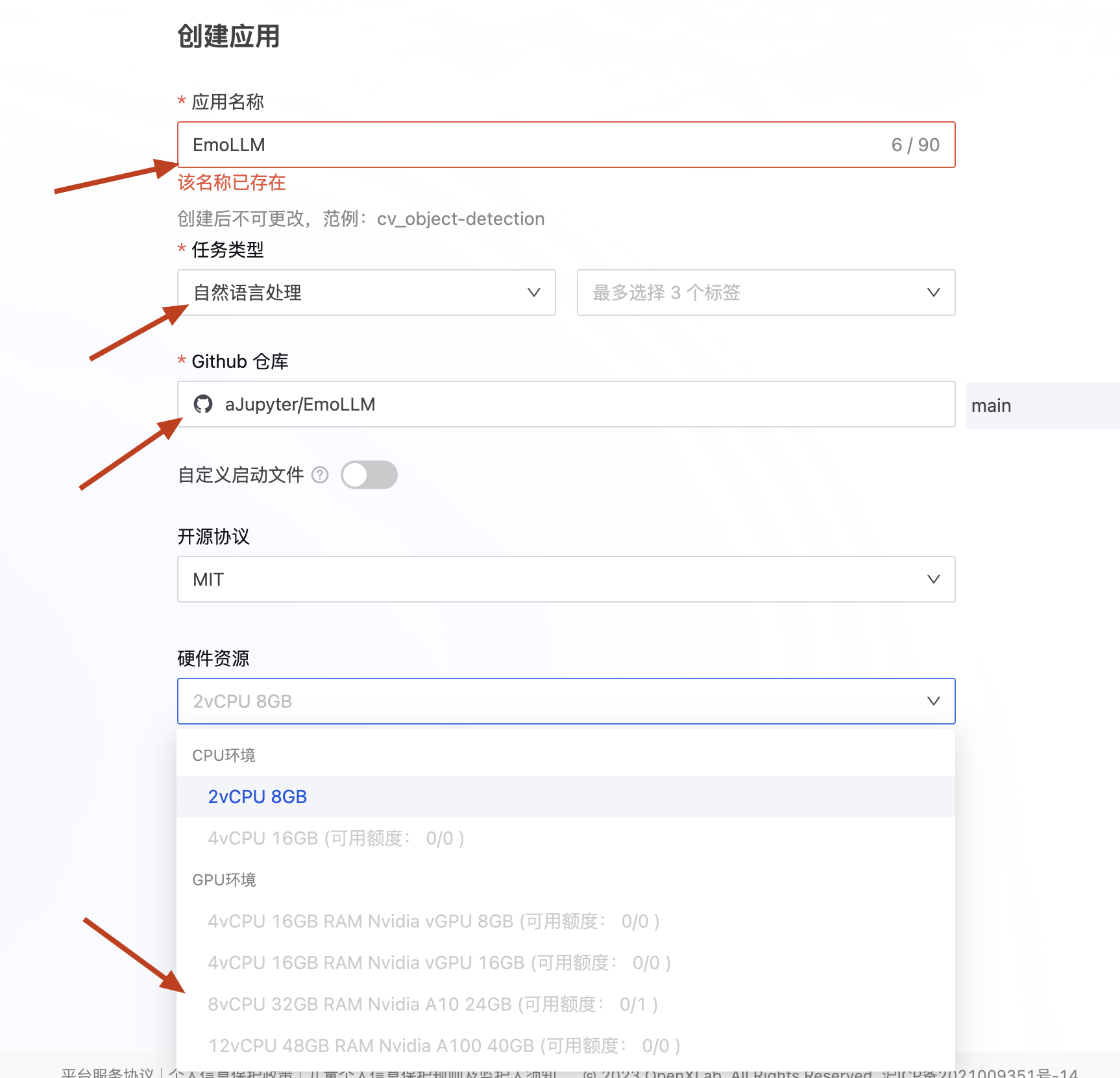
Deploy on OpenXLab
- Log in to OpenXLab and create a Gradio application

- Select configurations and create the project
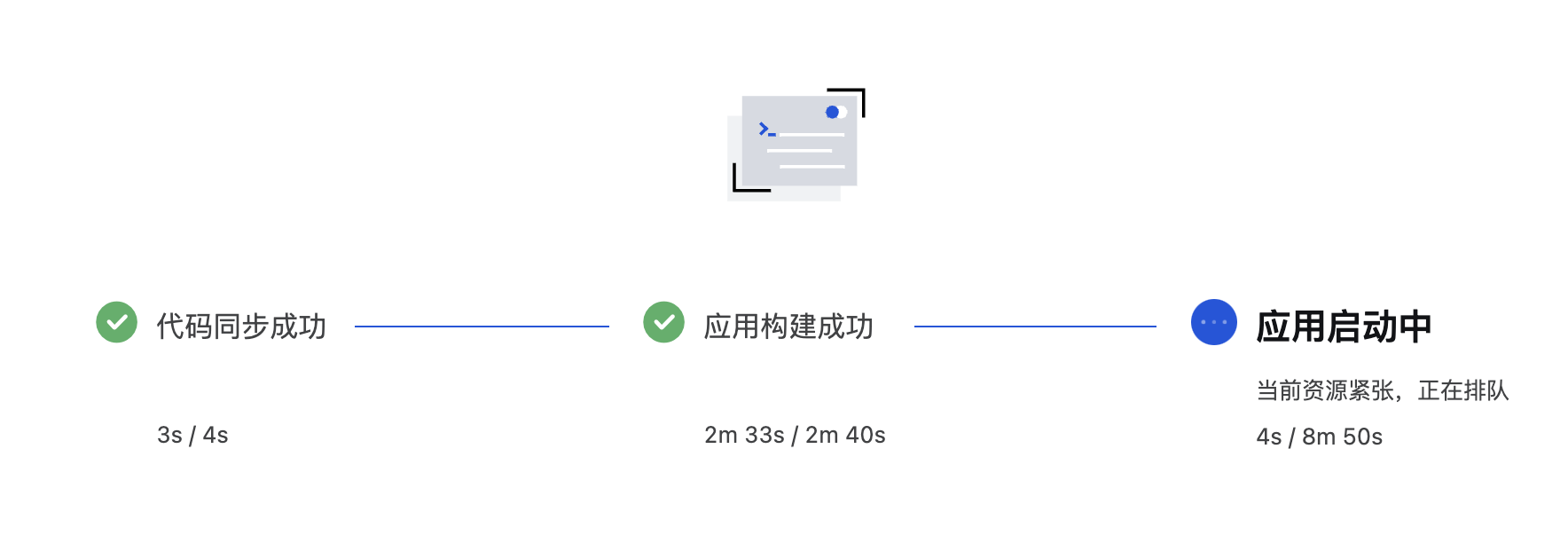
- Wait for the build and startup
- Try your own project
