* update rag/src/data_processing.py * Add files via upload allow user to load embedding & rerank models from cache * Add files via upload embedding_path = os.path.join(model_dir, 'embedding_model') rerank_path = os.path.join(model_dir, 'rerank_model') * 测试push dev 测试push dev * Add files via upload 两个母亲多轮对话数据集合并、清理和去重之后,得到 2439 条多轮对话数据(每条有6-8轮对话)。 * optimize deduplicate.py Add time print information save duplicate dataset as well remove print(content) * add base model qlora fintuning config file: internlm2_7b_base_qlora_e10_M_1e4_32_64.py * add full finetune code from internlm2 * other 2 configs for base model * update cli_internlm2.py three methods to load model 1. download model in openxlab 2. download model in modelscope 3. offline model * create upload_modelscope.py * add base model and update personal contributions * add README.md for Emollm_Scientist * Create README_internlm2_7b_base_qlora.md InternLM2 7B Base QLoRA 微调指南 * [DOC]EmoLLM_Scientist微调指南 * [DOC]EmoLLM_Scientist微调指南 * [DOC]EmoLLM_Scientist微调指南 * [DOC]EmoLLM_Scientist微调指南 * [DOC]EmoLLM_Scientist微调指南 * [DOC]EmoLLM_Scientist微调指南 * update * [DOC]README_scientist.md * delete config * format update * upload xlab * add README_Model_Uploading.md and images * modelscope model upload * Modify Recent Updates * update daddy-like Boy-Friend EmoLLM * update model uploading with openxlab * update model uploading with openxlab --------- Co-authored-by: zealot52099 <songyan5209@163.com> Co-authored-by: xzw <62385492+aJupyter@users.noreply.github.com> Co-authored-by: zealot52099 <67356208+zealot52099@users.noreply.github.com> Co-authored-by: Bryce Wang <90940753+brycewang2018@users.noreply.github.com> Co-authored-by: HongCheng <kwchenghong@gmail.com> |
||
|---|---|---|
| .. | ||
| cli_internlm2_scientist.py | ||
| cli_internlm2.py | ||
| cli_qwen.py | ||
| README_EN.md | ||
| README.md | ||
| requirements_qwen.txt | ||
| web_qwen.py | ||
Deploying Guide for EmoLLM
Local Deployment
- Clone repo
git clone https://github.com/aJupyter/EmoLLM.git
- Install dependencies
pip install -r requirements.txt
-
Download the model
-
Model weights:https://openxlab.org.cn/models/detail/jujimeizuo/EmoLLM_Model
-
Download via openxlab.model.download, see cli_internlm2 for details
from openxlab.model import download download(model_repo='jujimeizuo/EmoLLM_Model', output='model') -
You can also download manually and place it in the
./modeldirectory, then delete the above code.
-
-
cli_demo
python ./demo/cli_internlm2.py
- web_demo
python ./app.py
If deploying on a server, you need to configure local port mapping.
Deploy on OpenXLab
- Log in to OpenXLab and create a Gradio application

- Select configurations and create the project

- Wait for the build and startup
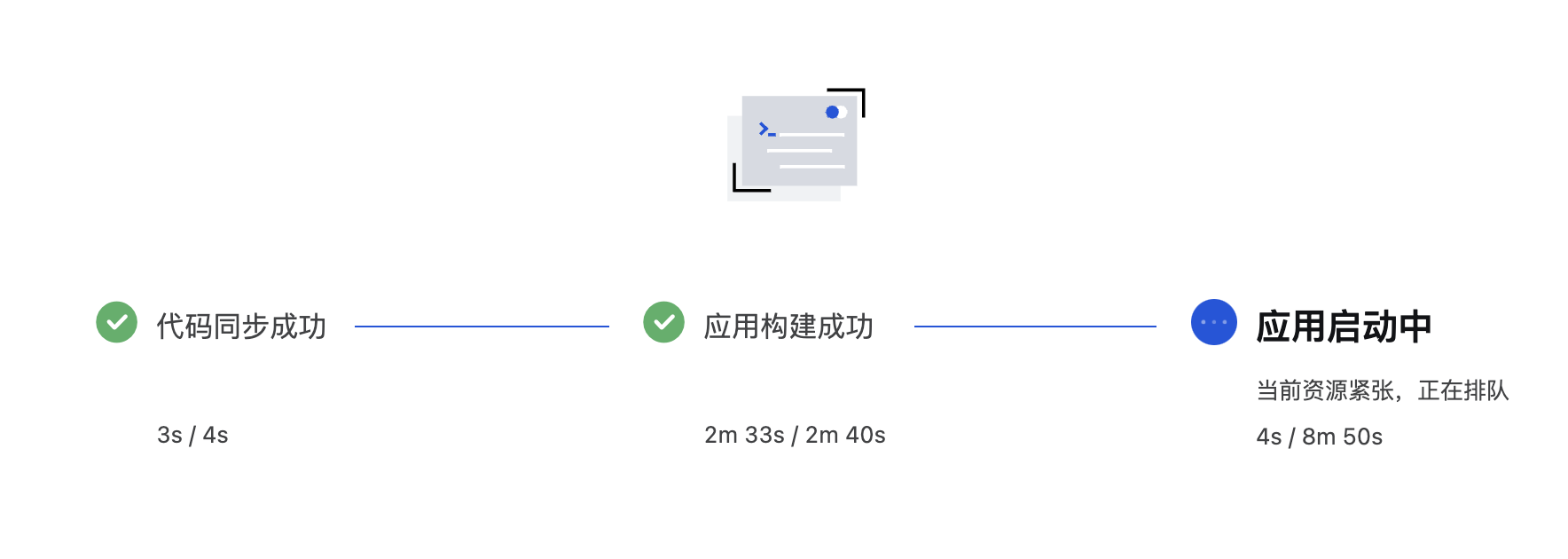
- Try your own project
