12 KiB
ChatGLM3-6B
Environment Preparation
In practice, we have two platforms available for selection.
- Rent a machine with a 3090 GPU and 24G memory on the autodl platform. Select the image as shown:
PyTorch-->2.0.0-->3.8(ubuntu20.04)-->11.8.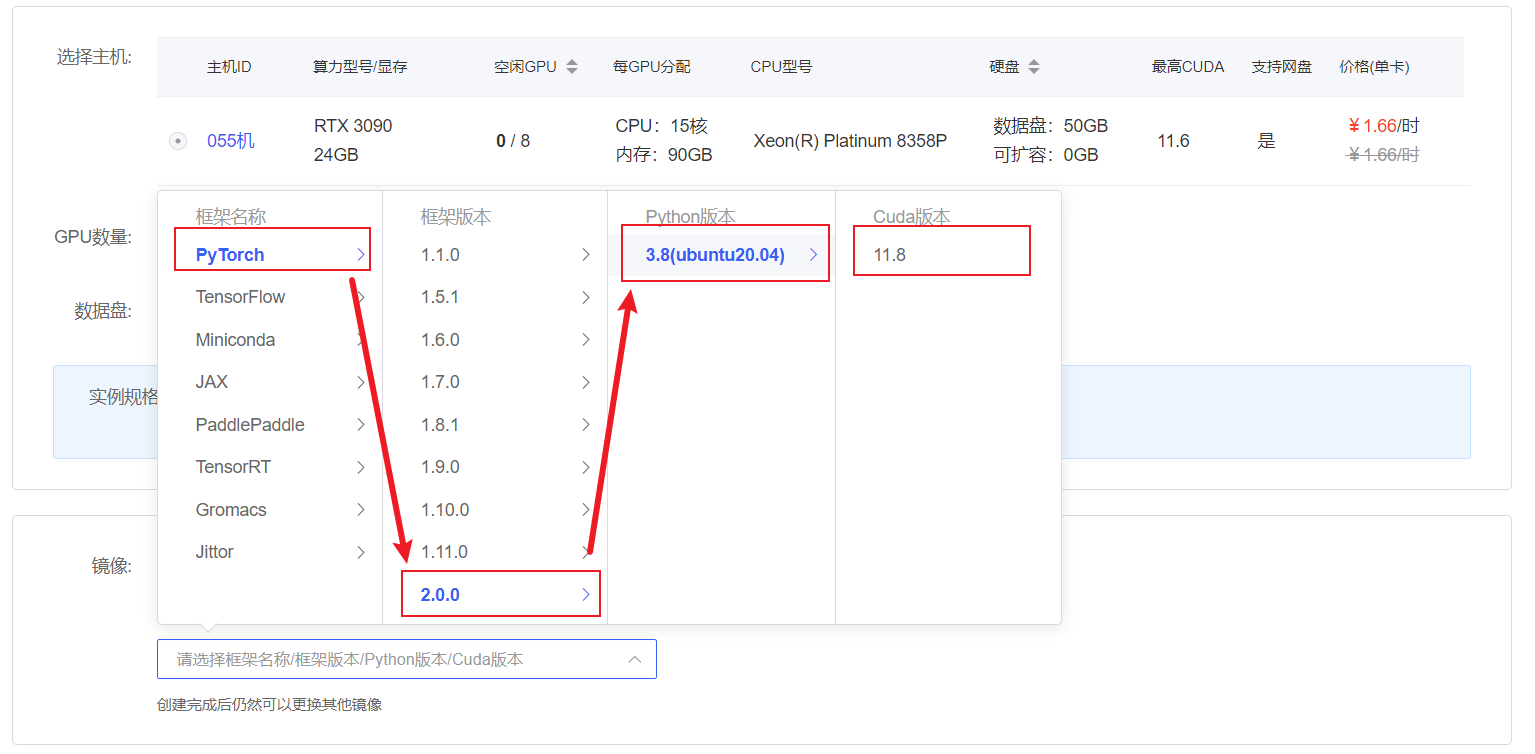
- On the InternStudio platform, choose the configuration of A100(1/4). Select the image as shown:
Cuda11.7-conda.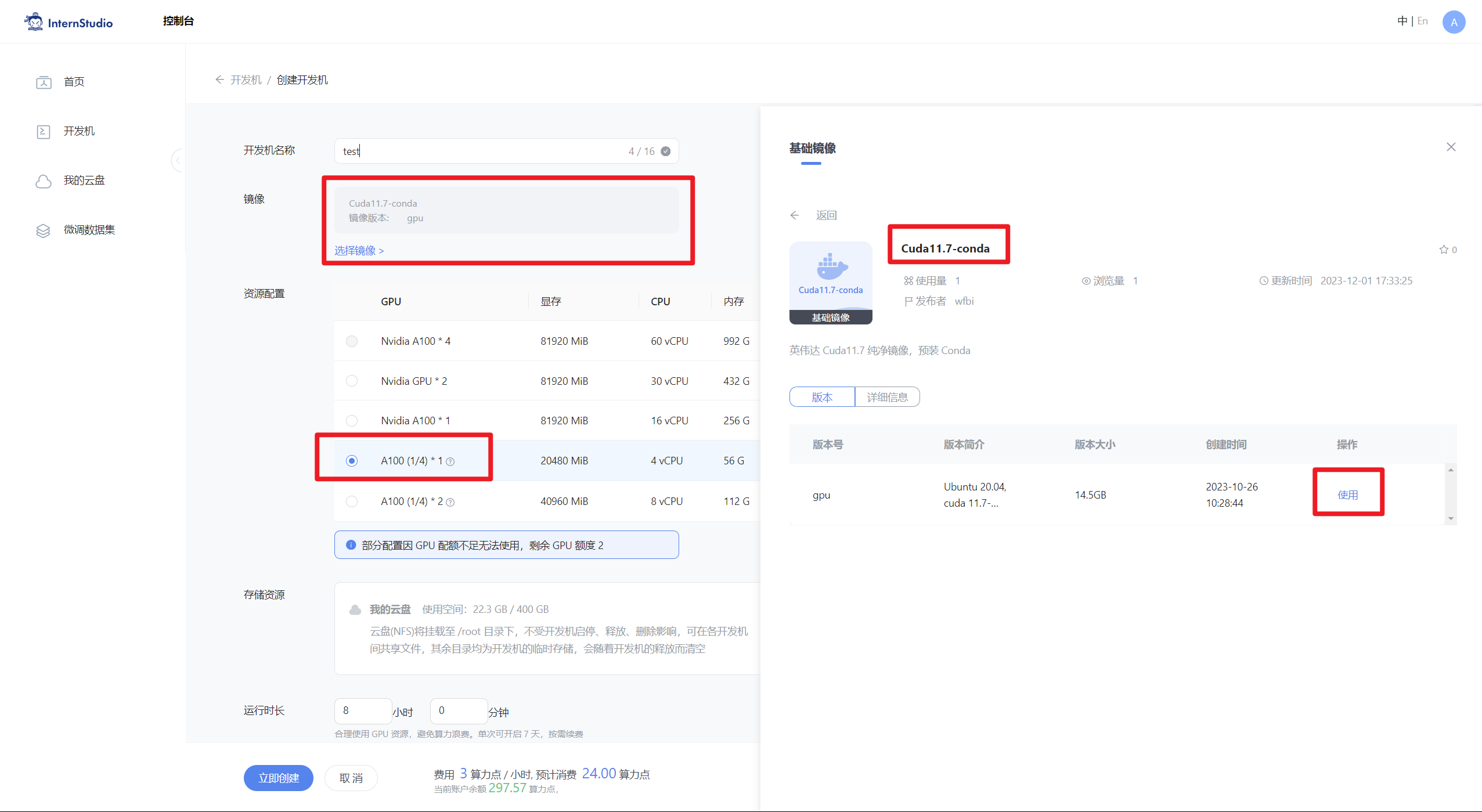
In the Terminal, update pip and install dependencies.
# Upgrade pip
python -m pip install --upgrade pip
pip install modelscope==1.9.5
pip install transformers==4.35.2
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.24.1
pip install peft==0.4.0
pip install datasets==2.10.1
Download Models
Use the modelscope function snapshot_download to download the model. The first parameter is the model name, and the parameter cache_dir is the download path of the model.
Create a download.py file in the /root/autodl-tmp directory and enter the following content. After pasting the code, remember to save the file as shown in the figure. Run python /root/autodl-tmp/download.py to execute the download. The model size is 14 GB, and the download will take about 10~20 minutes.
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('ZhipuAI/chatglm3-6b', cache_dir='/root/autodl-tmp', revision='master')
For more information about ChatLLM, please refer to self-llm
Construction of Instruction Set
Fine-tuning of LLM generally refers to the process of instruction tuning. Instruction tuning means that the fine-tuning data we use is in the form of:
{
"system":"Answer the following user question and only output the answer.",
"input":"1+1 equals what?",
"output":"2"
}
Among them, system is the user's instruction, informing the model of the task it needs to complete; input is the user's input, which is necessary input for completing the user's instruction; output is the output the model should give.
That is, our core training goal is to enable the model to have the ability to understand and follow user instructions. Therefore, when constructing the instruction set, we should build task instruction sets in a targeted manner according to our own tasks and objectives. Our goal is to build a personalized LLM that can simulate a psychological doctor solving psychological problems, so we construct instructions like this:
{
"system": "Now you are a psychological expert, I have some psychological problems, please help me solve them with professional knowledge.",
"input":"I feel like I always procrastinate and have trouble concentrating on completing tasks.",
"output":"Procrastination is a common problem, but it can be overcome. First, you can try to set yourself a clear goal and break it down into smaller tasks. This way, you will find the task easier to manage. In addition, maintaining a tidy and orderly work environment also helps improve work efficiency. Finally, when you complete a task, don't forget to give yourself some rewards to motivate yourself to keep moving forward."
}
Data Formatting
Data for Lora training needs to be formatted and encoded before being input into the model for training. As those familiar with the training process of Pytorch models know, we usually need to encode the input text as input_ids and the output text as labels, and the results of encoding are multi-dimensional vectors. We first define a preprocessing function that encodes the input and output text for each sample and returns an encoded dictionary:
def process_func(example):
MAX_LENGTH = 512
input_ids, labels = [], []
instruction = tokenizer.encode(text="\n".join(["<|system|>", "Now you are a psychological expert, I have some psychological problems, please help me solve them with your professional knowledge.", "<|user|>",
example["system"] + example["input"] + "<|assistant|>"]).strip() + "\n",
add_special_tokens=True, truncation=True, max_length=MAX_LENGTH)
response = tokenizer.encode(text=example["output"], add_special_tokens=False, truncation=True,
max_length=MAX_LENGTH)
input_ids = instruction + response + [tokenizer.eos_token_id]
labels = [tokenizer.pad_token_id] * len(instruction) + response + [tokenizer.eos_token_id]
pad_len = MAX_LENGTH - len(input_ids)
input_ids += [tokenizer.pad_token_id] * pad_len
labels += [tokenizer.pad_token_id] * pad_len
labels = [(l if l != tokenizer.pad_token_id else -100) for l in labels]
return {
"input_ids": input_ids,
"labels": labels
}
After formatting, each piece of data sent into the model is a dictionary containing two key-value pairs: input_ids and labels. input_ids is the encoding of the input text, and labels is the encoding of the output text. The decoded result should appear as follows:
[gMASK]sop <|system|>
Now you are a psychological expert, I have some psychological problems, please help me solve them with your professional knowledge.
<|user|>
My team atmosphere is great, and all my colleagues are very friendly. Moreover, we often go out together to play, feeling like a big family.\n <|assistant|>
This is a great working environment, and having good interpersonal relationships and teamwork can indeed bring a lot of happiness. However, I also understand that you may encounter some challenges in your work, such as task pressure or conflicts with colleagues. Have you ever thought about how to deal with these issues?
Why is it in this form? That's a great question! Different models have different formatting requirements for their inputs, so we need to refer to the training source code of our deep model to check the specific format. Since fine-tuning Lora based on the original model instructions should yield the best results, we still follow the input format of the original model. Ok, here is the link to the source code for those who are interested in exploring it on their own:
hugging face ChatGLM3 repository: The InputOutputDataset class can be found here.
Additionally, you can refer to this repository for data processing of ChatGLM LLaMA-Factory.
Loading the tokenizer and half-precision model
The model is loaded in half-precision format. If you have a newer graphics card, you can use torch.bfolat to load it. For custom models, always specify the trust_remote_code parameter as True.
tokenizer = AutoTokenizer.from_pretrained('./model/chatglm3-6b', use_fast=False, trust_remote_code=True)
# The model is loaded in half-precision format. If you have a relatively new GPU, you can load it in torch.bfloat format.
model = AutoModelForCausalLM.from_pretrained('./model/chatglm3-6b', trust_remote_code=True, torch_dtype=torch.half, device_map="auto")
Defining LoraConfig
The LoraConfig class allows you to set many parameters, but there are only a few main ones. I'll briefly explain them; those interested can directly refer to the source code.
task_type: The type of the model.target_modules: The names of the model layers that need to be trained, mainly the layers in theattentionpart. The names of these layers differ for different models. They can be passed as an array, a string, or a regular expression.r: The rank oflora, which can be seen in the principles ofLora.lora_alpha: TheLora alaph, the specific role of which can be referred to in the principles ofLora.modules_to_savespecifies which modules, besides those split intolora, can be fully specified for training.
What's this scaling of Lora about? Obviously, it's not r (rank). This scaling is actually lora_alpha/r, and in this LoraConfig, the scaling is 4 times.
This scaling does not change the size of the parameters of LoRa; it essentially involves broadcasting the parameter values and performing linear scaling.
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["query_key_value"],
inference_mode=False, # training mode
r=8, # Lora Rank
lora_alpha=32, # Lora alaph,for specific details and functionality, please refer to the Lora principle.
lora_dropout=0.1 # Dropout ratio
)
Customizing TrainingArguments Parameters
The source code of the TrainingArguments class also introduces the specific functions of each parameter. Of course, everyone is encouraged to explore it on their own, but I'll mention a few commonly used ones here.
output_dir: The output path for the model.per_device_train_batch_size: As the name suggests,batch_size.gradient_accumulation_steps: Gradient accumulation. If you have a smaller GPU memory, you can set a smallerbatch_sizeand increase the gradient accumulation.logging_steps: How many steps to output alog.num_train_epochs: As the name suggests,epoch.gradient_checkpointing: Gradient checking. Once enabled, the model must executemodel.enable_input_require_grads(). The principle behind this can be explored by yourselves, so I won't go into details here.
# The GLM source repository has restructured its own data_collator and we will continue to use it here.
data_collator = DataCollatorForSeq2Seq(
tokenizer,
model=model,
label_pad_token_id=-100,
pad_to_multiple_of=None,
padding=False
)
args = TrainingArguments(
output_dir="./output/ChatGLM",
per_device_train_batch_size=4,
gradient_accumulation_steps=2,
logging_steps=10,
num_train_epochs=3,
gradient_checkpointing=True,
save_steps=100,
learning_rate=1e-4,
)
Training with Trainer
Put the model in, put the parameters set above in, and put the dataset in. OK! Start training!
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_id,
data_collator=data_collator,
)
trainer.train()
Inference
You can use this more classic method for inference.
while True:
# 推理
model = model.cuda()
input_text = input("User >>>")
ipt = tokenizer("<|system|>\nNow you are a mental health expert, and I have some psychological issues. Please use your professional knowledge to help me solve them.\n<|user|>\n {}\n{}".format(input_text, "").strip() + "<|assistant|>\n", return_tensors="pt").to(model.device)
print(tokenizer.decode(model.generate(**ipt, max_length=128, do_sample=True)[0], skip_special_tokens=True))
Reloading
Models fine-tuned through PEFT can be reloaded and inferred using the following methods:
- Load the source model and tokenizer;
- Use
PeftModelto merge the source model with the parameters fine-tuned by PEFT.
from peft import PeftModel
model = AutoModelForCausalLM.from_pretrained("./model/chatglm3-6b", trust_remote_code=True, low_cpu_mem_usage=True)
tokenizer = AutoTokenizer.from_pretrained("./model/chatglm3-6b", use_fast=False, trust_remote_code=True)
# Load the LoRa weights obtained from training.
p_model = PeftModel.from_pretrained(model, model_id="./output/ChatGLM/checkpoint-1000/")
while True:
# inference
model = model.cuda()
input_text = input("User >>>")
ipt = tokenizer("<|system|>\nNow you are a mental health expert, and I have some psychological issues. Please use your professional knowledge to help me solve them.\n<|user|>\n {}\n{}".format(input_text, "").strip() + "<|assistant|>\n", return_tensors="pt").to(model.device)
print(tokenizer.decode(model.generate(**ipt, max_length=128, do_sample=True)[0], skip_special_tokens=True))