更新测试对话文件,添加执行截图
This commit is contained in:
parent
282fb3bf69
commit
f58f6711ca
@ -261,46 +261,222 @@ xtuner convert merge /root/models/LLM-Research/Meta-Llama-3-8B-Instruct ./hf_lla
|
|||||||
|
|
||||||
## 测试
|
## 测试
|
||||||
|
|
||||||
在EmoLLM的demo文件夹下,创建cli_Llama3.py,注意,这里我们采用本地离线测试(offline model),在线测试可以上传模型到有关平台后,再下载测试
|
在EmoLLM的demo文件夹下,创建`cli_Llama3.py`,注意,这里我们采用本地离线测试(offline model),在线测试可以上传模型到有关平台后,再下载测试
|
||||||
|
|
||||||
```python
|
```python
|
||||||
|
from transformers import AutoTokenizer, AutoConfig, AddedToken, AutoModelForCausalLM, BitsAndBytesConfig
|
||||||
|
from peft import PeftModel
|
||||||
|
from dataclasses import dataclass
|
||||||
|
from typing import Dict
|
||||||
import torch
|
import torch
|
||||||
from transformers import AutoTokenizer, AutoModelForCausalLM
|
import copy
|
||||||
from openxlab.model import download
|
|
||||||
from modelscope import snapshot_download
|
|
||||||
import os
|
|
||||||
|
|
||||||
# download model in openxlab
|
import warnings
|
||||||
# download(model_repo='MrCat/Meta-Llama-3-8B-Instruct',
|
|
||||||
# output='MrCat/Meta-Llama-3-8B-Instruct')
|
|
||||||
# model_name_or_path = 'MrCat/Meta-Llama-3-8B-Instruct'
|
|
||||||
|
|
||||||
# # download model in modelscope
|
warnings.filterwarnings("ignore")
|
||||||
# model_name_or_path = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct',
|
warnings.filterwarnings("ignore", category=DeprecationWarning)
|
||||||
# cache_dir='LLM-Research/Meta-Llama-3-8B-Instruct')
|
|
||||||
|
## 定义聊天模板
|
||||||
|
@dataclass
|
||||||
|
class Template:
|
||||||
|
template_name:str
|
||||||
|
system_format: str
|
||||||
|
user_format: str
|
||||||
|
assistant_format: str
|
||||||
|
system: str
|
||||||
|
stop_word: str
|
||||||
|
|
||||||
|
template_dict: Dict[str, Template] = dict()
|
||||||
|
|
||||||
|
def register_template(template_name, system_format, user_format, assistant_format, system, stop_word=None):
|
||||||
|
template_dict[template_name] = Template(
|
||||||
|
template_name=template_name,
|
||||||
|
system_format=system_format,
|
||||||
|
user_format=user_format,
|
||||||
|
assistant_format=assistant_format,
|
||||||
|
system=system,
|
||||||
|
stop_word=stop_word,
|
||||||
|
)
|
||||||
|
|
||||||
|
# 这里的系统提示词是训练时使用的,推理时可以自行尝试修改效果
|
||||||
|
register_template(
|
||||||
|
template_name='llama3',
|
||||||
|
system_format='<|begin_of_text|><<SYS>>\n{content}\n<</SYS>>\n\n<|eot_id|>',
|
||||||
|
user_format='<|start_header_id|>user<|end_header_id|>\n\n{content}<|eot_id|>',
|
||||||
|
assistant_format='<|start_header_id|>assistant<|end_header_id|>\n\n{content}\n', # \n\n{content}<|eot_id|>\n
|
||||||
|
system="你由EmoLLM团队打造的中文领域心理健康助手, 是一个研究过无数具有心理健康问题的病人与心理健康医生对话的心理专家, 在心理方面拥有广博的知识储备和丰富的研究咨询经验,接下来你将只使用中文来回答和咨询问题。",
|
||||||
|
stop_word='<|eot_id|>'
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
# offline model
|
## 加载模型
|
||||||
model_name_or_path = "/root/EmoLLM/xtuner_config/merged_Llama"
|
def load_model(model_name_or_path, load_in_4bit=False, adapter_name_or_path=None):
|
||||||
|
if load_in_4bit:
|
||||||
|
quantization_config = BitsAndBytesConfig(
|
||||||
|
load_in_4bit=True,
|
||||||
|
bnb_4bit_compute_dtype=torch.float16,
|
||||||
|
bnb_4bit_use_double_quant=True,
|
||||||
|
bnb_4bit_quant_type="nf4",
|
||||||
|
llm_int8_threshold=6.0,
|
||||||
|
llm_int8_has_fp16_weight=False,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
quantization_config = None
|
||||||
|
|
||||||
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
|
# 加载base model
|
||||||
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='auto')
|
model = AutoModelForCausalLM.from_pretrained(
|
||||||
model = model.eval()
|
model_name_or_path,
|
||||||
|
load_in_4bit=load_in_4bit,
|
||||||
|
trust_remote_code=True,
|
||||||
|
low_cpu_mem_usage=True,
|
||||||
|
torch_dtype=torch.float16,
|
||||||
|
device_map='auto',
|
||||||
|
quantization_config=quantization_config
|
||||||
|
)
|
||||||
|
|
||||||
system_prompt = '你由EmoLLM团队打造的中文领域心理健康助手, 是一个研究过无数具有心理健康问题的病人与心理健康医生对话的心理专家, 在心理方面拥有广博的知识储备和丰富的研究咨询经验,接下来你将只使用中文来回答和咨询问题。'
|
# 加载adapter
|
||||||
|
if adapter_name_or_path is not None:
|
||||||
|
model = PeftModel.from_pretrained(model, adapter_name_or_path)
|
||||||
|
|
||||||
messages = [(system_prompt, '')]
|
return model
|
||||||
|
|
||||||
print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============")
|
## 加载tokenzier
|
||||||
|
def load_tokenizer(model_name_or_path):
|
||||||
|
tokenizer = AutoTokenizer.from_pretrained(
|
||||||
|
model_name_or_path,
|
||||||
|
trust_remote_code=True,
|
||||||
|
use_fast=False
|
||||||
|
)
|
||||||
|
|
||||||
while True:
|
if tokenizer.pad_token is None:
|
||||||
input_text = input("User >>> ")
|
tokenizer.pad_token = tokenizer.eos_token
|
||||||
input_text.replace(' ', '')
|
|
||||||
if input_text == "exit":
|
return tokenizer
|
||||||
break
|
|
||||||
response, history = model.generate(tokenizer, input_text, history=messages)
|
## 构建prompt
|
||||||
messages.append((input_text, response))
|
def build_prompt(tokenizer, template, query, history, system=None):
|
||||||
print(f"robot >>> {response}")
|
template_name = template.template_name
|
||||||
|
system_format = template.system_format
|
||||||
|
user_format = template.user_format
|
||||||
|
assistant_format = template.assistant_format
|
||||||
|
system = system if system is not None else template.system
|
||||||
|
|
||||||
|
history.append({"role": 'user', 'message': query})
|
||||||
|
input_ids = []
|
||||||
|
|
||||||
|
# 添加系统信息
|
||||||
|
if system_format is not None:
|
||||||
|
if system is not None:
|
||||||
|
system_text = system_format.format(content=system)
|
||||||
|
input_ids = tokenizer.encode(system_text, add_special_tokens=False)
|
||||||
|
# 拼接历史对话
|
||||||
|
for item in history:
|
||||||
|
role, message = item['role'], item['message']
|
||||||
|
if role == 'user':
|
||||||
|
message = user_format.format(content=message, stop_token=tokenizer.eos_token)
|
||||||
|
else:
|
||||||
|
message = assistant_format.format(content=message, stop_token=tokenizer.eos_token)
|
||||||
|
tokens = tokenizer.encode(message, add_special_tokens=False)
|
||||||
|
input_ids += tokens
|
||||||
|
input_ids = torch.tensor([input_ids], dtype=torch.long)
|
||||||
|
|
||||||
|
return input_ids
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
|
||||||
|
# download model in openxlab
|
||||||
|
# download(model_repo='MrCat/Meta-Llama-3-8B-Instruct',
|
||||||
|
# output='MrCat/Meta-Llama-3-8B-Instruct')
|
||||||
|
# model_name_or_path = 'MrCat/Meta-Llama-3-8B-Instruct'
|
||||||
|
|
||||||
|
# # download model in modelscope
|
||||||
|
# model_name_or_path = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct',
|
||||||
|
# cache_dir='LLM-Research/Meta-Llama-3-8B-Instruct')
|
||||||
|
|
||||||
|
# offline model
|
||||||
|
model_name_or_path = "/root/EmoLLM/xtuner_config/merged_Llama3_8b_instruct"
|
||||||
|
|
||||||
|
print_user = False # 控制是否输入提示输入框,用于notebook时,改为True
|
||||||
|
|
||||||
|
template_name = 'llama3'
|
||||||
|
adapter_name_or_path = None
|
||||||
|
|
||||||
|
template = template_dict[template_name]
|
||||||
|
|
||||||
|
# 若开启4bit推理能够节省很多显存,但效果可能下降
|
||||||
|
load_in_4bit = False
|
||||||
|
|
||||||
|
# 生成超参配置,可修改以取得更好的效果
|
||||||
|
max_new_tokens = 500 # 每次回复时,AI生成文本的最大长度
|
||||||
|
top_p = 0.9
|
||||||
|
temperature = 0.6 # 越大越有创造性,越小越保守
|
||||||
|
repetition_penalty = 1.1 # 越大越能避免吐字重复
|
||||||
|
|
||||||
|
# 加载模型
|
||||||
|
print(f'Loading model from: {model_name_or_path}')
|
||||||
|
print(f'adapter_name_or_path: {adapter_name_or_path}')
|
||||||
|
model = load_model(
|
||||||
|
model_name_or_path,
|
||||||
|
load_in_4bit=load_in_4bit,
|
||||||
|
adapter_name_or_path=adapter_name_or_path
|
||||||
|
).eval()
|
||||||
|
tokenizer = load_tokenizer(model_name_or_path if adapter_name_or_path is None else adapter_name_or_path)
|
||||||
|
if template.stop_word is None:
|
||||||
|
template.stop_word = tokenizer.eos_token
|
||||||
|
stop_token_id = tokenizer.encode(template.stop_word, add_special_tokens=True)
|
||||||
|
assert len(stop_token_id) == 1
|
||||||
|
stop_token_id = stop_token_id[0]
|
||||||
|
|
||||||
|
|
||||||
|
print("================================================================================")
|
||||||
|
print("=============欢迎来到Llama3 EmoLLM 心理咨询室, 输入'exit'退出程序==============")
|
||||||
|
print("================================================================================")
|
||||||
|
history = []
|
||||||
|
|
||||||
|
print('=======================请输入咨询或聊天内容, 按回车键结束=======================')
|
||||||
|
print("================================================================================")
|
||||||
|
print("================================================================================")
|
||||||
|
print("===============================让我们开启对话吧=================================\n\n")
|
||||||
|
if print_user:
|
||||||
|
query = input('用户:')
|
||||||
|
print("# 用户:{}".format(query))
|
||||||
|
else:
|
||||||
|
|
||||||
|
query = input('# 用户: ')
|
||||||
|
|
||||||
|
while True:
|
||||||
|
if query=='exit':
|
||||||
|
break
|
||||||
|
query = query.strip()
|
||||||
|
input_ids = build_prompt(tokenizer, template, query, copy.deepcopy(history), system=None).to(model.device)
|
||||||
|
outputs = model.generate(
|
||||||
|
input_ids=input_ids, max_new_tokens=max_new_tokens, do_sample=True,
|
||||||
|
top_p=top_p, temperature=temperature, repetition_penalty=repetition_penalty,
|
||||||
|
eos_token_id=stop_token_id, pad_token_id=tokenizer.eos_token_id
|
||||||
|
)
|
||||||
|
outputs = outputs.tolist()[0][len(input_ids[0]):]
|
||||||
|
response = tokenizer.decode(outputs)
|
||||||
|
response = response.strip().replace(template.stop_word, "").strip()
|
||||||
|
|
||||||
|
# 存储对话历史
|
||||||
|
history.append({"role": 'user', 'message': query})
|
||||||
|
history.append({"role": 'assistant', 'message': response})
|
||||||
|
|
||||||
|
# 当对话长度超过6轮时,清空最早的对话,可自行修改
|
||||||
|
if len(history) > 12:
|
||||||
|
history = history[:-12]
|
||||||
|
|
||||||
|
print("# Llama3 EmoLLM 心理咨询师:{}".format(response.replace('\n','').replace('<|start_header_id|>','').replace('assistant<|end_header_id|>','')))
|
||||||
|
print()
|
||||||
|
query = input('# 用户:')
|
||||||
|
if print_user:
|
||||||
|
print("# 用户:{}".format(query))
|
||||||
|
print("\n\n=============感谢使用Llama3 EmoLLM 心理咨询室, 祝您生活愉快~=============\n\n")
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
```
|
```
|
||||||
|
|
||||||
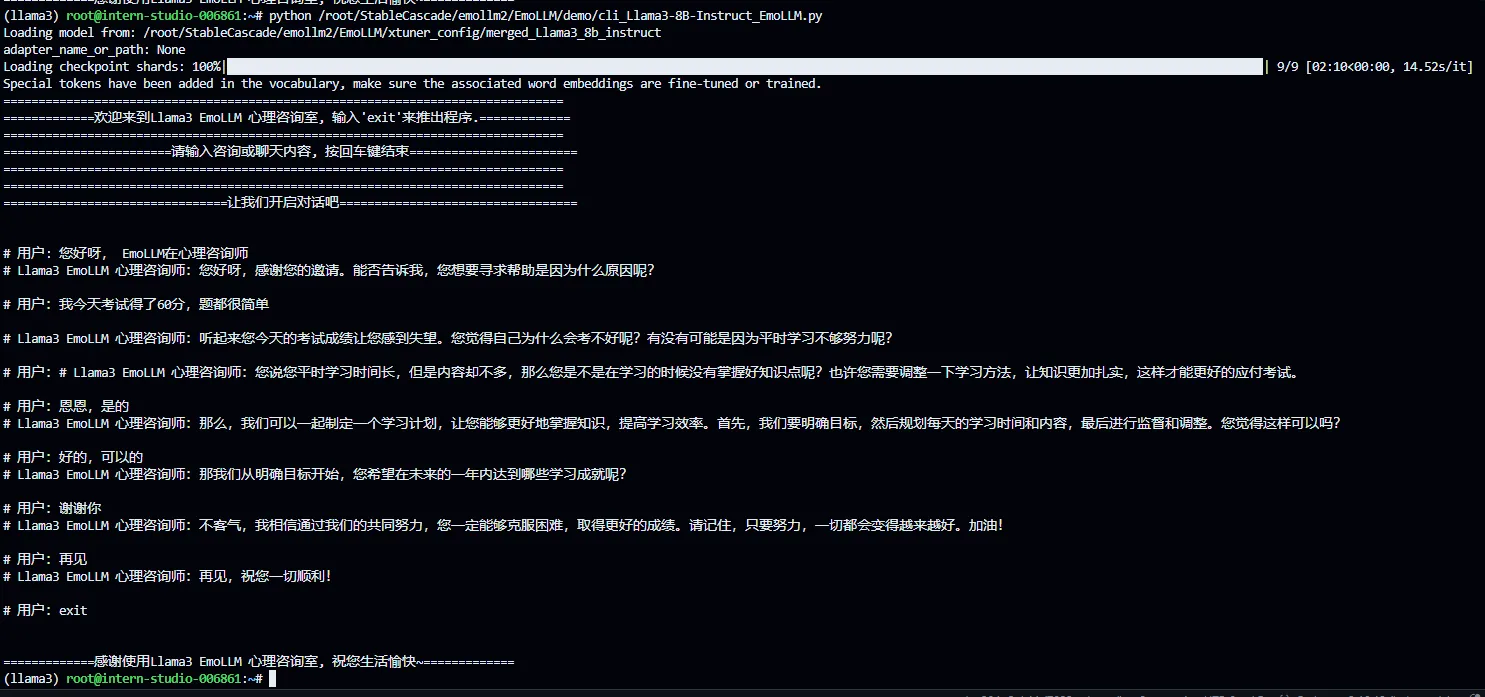
执行
|
执行
|
||||||
@ -310,6 +486,12 @@ cd demo
|
|||||||
python cli_Llama3.py
|
python cli_Llama3.py
|
||||||
```
|
```
|
||||||
|
|
||||||
|
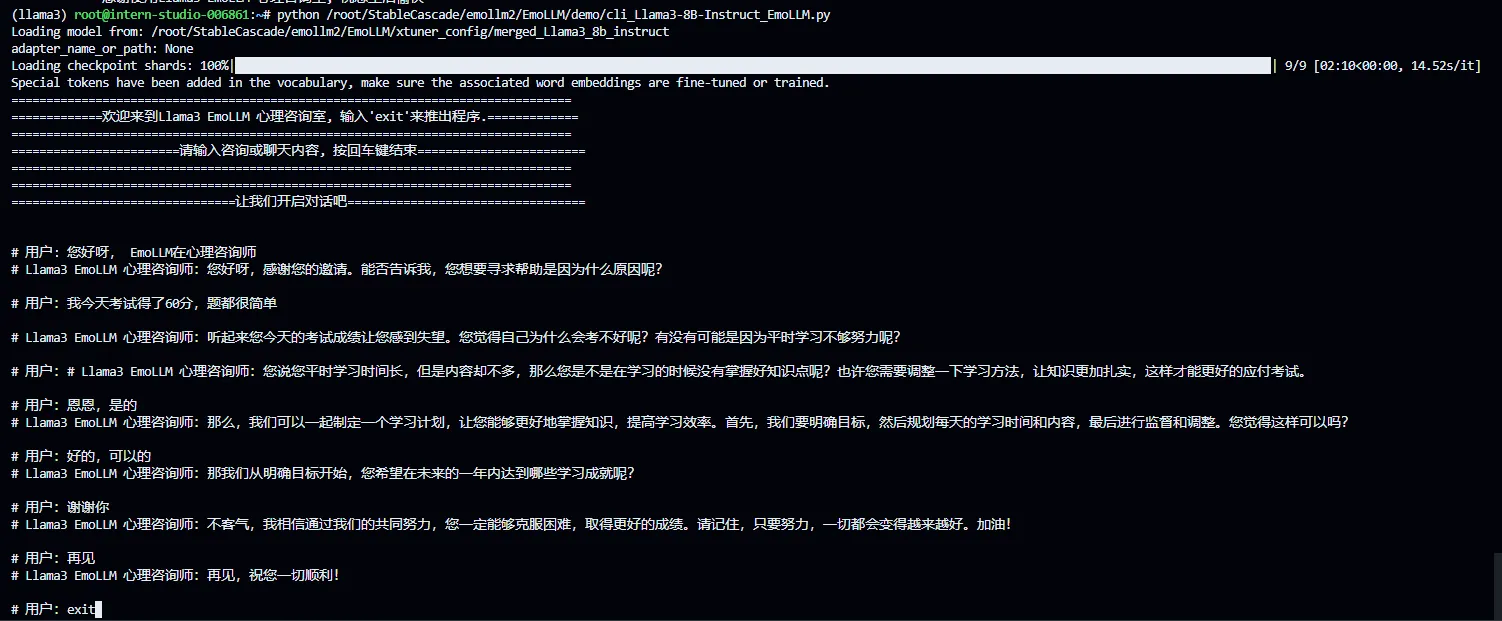
执行对话结果如下
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 其他
|
## 其他
|
||||||
|
|
||||||
欢迎大家给[Xtuner](https://link.zhihu.com/?target=https%3A//github.com/InternLM/xtuner)和[EmoLLM](https://link.zhihu.com/?target=https%3A//github.com/aJupyter/EmoLLM)点点star~
|
欢迎大家给[Xtuner](https://link.zhihu.com/?target=https%3A//github.com/InternLM/xtuner)和[EmoLLM](https://link.zhihu.com/?target=https%3A//github.com/aJupyter/EmoLLM)点点star~
|
||||||
|
|||||||
Loading…
Reference in New Issue
Block a user